2022-01-03
High Performance GEMM in Plain C
- 2023-07-12
-
Mention analytical derivation of block sizes.
With reference to a previous item, this might be GCC is Better than Supposed, Part 3, but I’m not sure that’s fair.
Some time ago I pushed for an efficient implementation of the BLIS ‘reference’ GEMM micro-kernel to replace a naïve triple loop, and that was implemented. With the new implementation at the time I reported about ⅔ the performance with GCC of the assembler-based Haswell micro-kernel on DGEMM. That didn’t seem too bad. However, revisiting it, we can do better, > 80%.
The improvement is due to choosing block sizesThere’s now a
change to make that easier.
Note that block sizes can be derived analytically for a reasonable architecture model, providing at
least a first attempt if using the C micro-kernel for a new architecture.
the same as those for the hand-optimized version, not the reference defaults,
and turning on GCC unrolling (which should be done generally for the reference
kernels, and currently isn’t). The crucial MR/NR loop nest gets fully
unrolled and vectorized, as expected of a hand-optimized kernel.As
far as I know, there’s no need for the omp simd pragmas that BLIS
has, at least not with at all recent GCC.
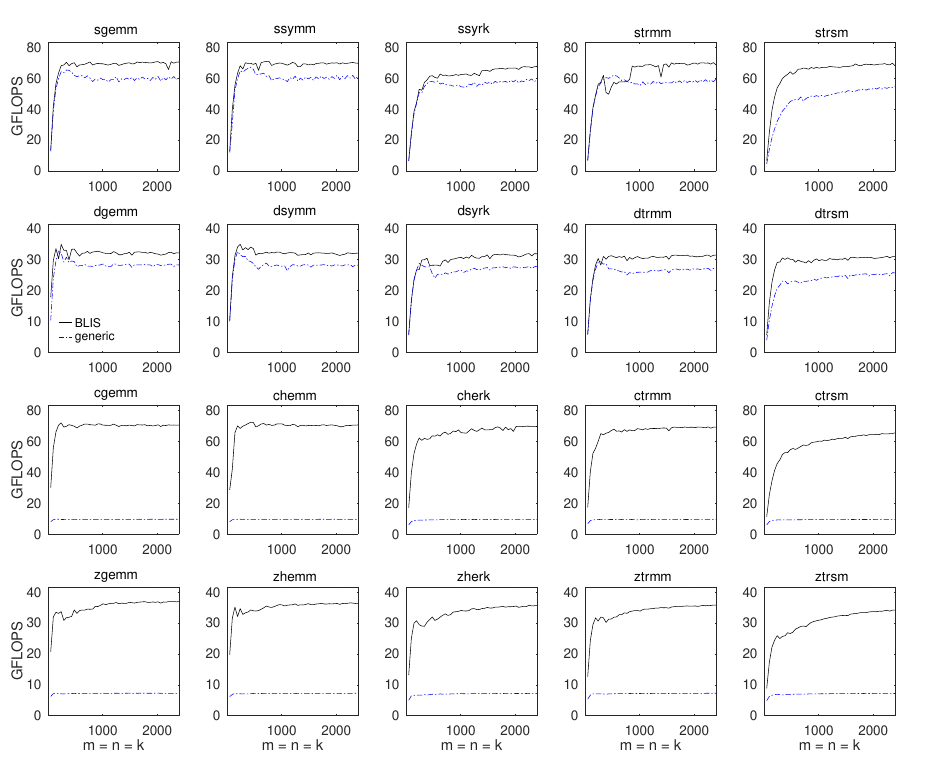
Results for BLIS’ test/3 BLAS level 3 performance tests are shown
below for an AVX2 target.Under a quiet 2.3GHz Intel i5-6200U
desktop. The performance seems to be subject to perturbation even though
it’s quiet, but the ratio of the plateaux seems reliable to 1%.
Considering the average of the five largest matrix sizes for DGEMM, where the
performance plateau has been reached, the reference kernel achieves 88% of
the performance of the optimized assembler version.
Given the compiler unrolling and vectorization, the performance gap is
expected to be down to the prefetching done by the assembler micro-kernel
(perhaps consistent with the closer performance at smaller dimensions).
However, departing from plain C, and using GCC’s __builtin_prefetch to
mirror the assembler kernel didn’t help.Also, turning off the GCC
default -fprefetch-loop-arrays had no effect on the generated code,
but it is only documented as relevant for ‘large arrays’.
The initial
prefetch block had no significant effect, and adding the others in the main
loop actually reduced performance. That obviously bears re-visiting; I’m not
good with assembler, and haven’t tried to compare what GCC generates with the
manual effort.
You’ll notice the complex operations perform very poorly; they aren’t
vectorized. That’s because BLIS represents complex values as a struct — a
classic vectorization blocker.Traditionally to be compared with
Fortran’s typically-vectorizable COMPLEX.
The support for using
C99 complex (guarded by BLIS_ENABLE_C99_COMPLEX) won’t build,
and probably needs substantial changes. At least some form of assignment
abstraction is needed to avoid creal and cimag in lvalue
positions. Doing that work should allow vectorization of complex kernels. (I
checked an example with the micro-kernel structure.)
The situation with Skylake-X (AVX512) is different, and needs more
investigation. The best relative results I got are much worse than for
AVX2.Using -mprefer-vector-width=512 for the kernels, not the
default 256.
Complex prefetch is known to be important for the optimized
micro-kernels, and the block sizes for the skx configuration seem to
be inappropriate for the generic code.
I also looked at POWER9, since I’m working with that. The BLIS
power9 configuration is broken, and so wasn’t comapred; it fails the
self-tests and gives unrealistically high performance. However, the reference
version achieved around 77% of the performance of OpenBLAS 0.3.15, but only
58% of IBM ESSL, with a 6 × 12 micro-kernel and other block sizes like
the BLIS power9 configuration. Perhaps that can be improved but, as
with Haswell, a prefetch block before the MR/NR loop nest made no difference.